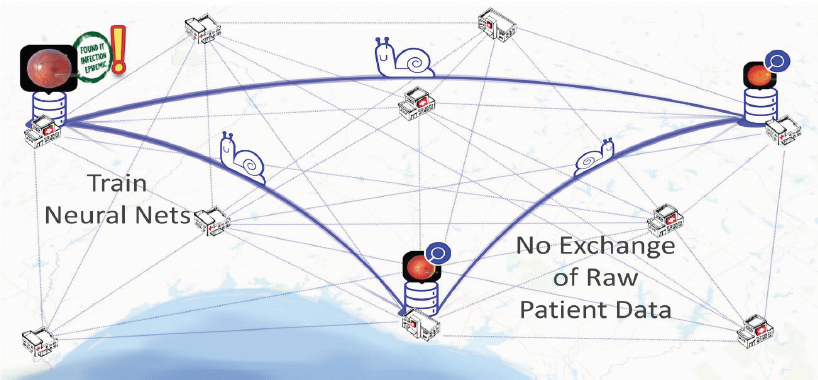
Split Learning: Distributed and collaborative learning
Credit:
https://arxiv.org/pdf/1812.00564.pdf
Abstract: Can a server utilize deep learning models for training or inference without accessing raw data from clients? Split learning naturally allows for various configurations of cooperating entities to train (and infer from) machine learning models without sharing any raw data or detailed information about the model.
Key Idea: In the simplest of configurations of split learning, each client (for example, radiology center) trains a partial deep network up to a specific layer known as the cut layer. The outputs at the cut layer are sent to another entity (server/another client) which completes the rest of the training without looking at raw data from any client that holds the raw data. This completes a round of forward propagation without sharing raw data. The gradients are now back propagated again from its last layer until the cut layer in a similar fashion. The gradients at the cut layer (and only these gradients) are sent back to radiology client centers. The rest of back propagation is now completed at the radiology client centers. This process is continued until the distributed split learning network is trained without looking at each others raw data.
Split learning’s computational and communication efficiency on clients:
Client-side communication costs are significantly reduced as the data to be transmitted is restricted to initial layers of the split learning network (splitNN) prior to the split. The client-side computation costs of learning the weights of the network are also significantly reduced for the same reason. In terms of model performance, the accuracies of Split NN remained competitive to other distributed deep learning methods like federated learning and large batch synchronous SGD with a drastically smaller client side computational burden when training on a larger number of clients as shown below in terms of teraflops of computation and gigabytes of communication when split learning is used to train Resnet and VGG architectures over 100 and 500 clients with CIFAR 10 and CIFAR 100 datasets.
Versatile plug-and-play configurations of split learning
Versatile configurations of split learning configurations cater to various practical settings of i) multiple entities holding different modalities of patient data, ii) centralized and local health entities collaborating on multiple tasks, iii) learning without sharing labels, iv) multi-task split learning, v) multi-hop split learning and other hybrid possibilities to name a few as shown below and further detailed in our paper here (PDF).
RESEARCH AREAS
Computation
Machine Learning
IMPACT AREAS
Big Data
Finance
Healthcare / Medicine
Infrastructure
Manufacturing
Social Networks
RESEARCH AREAS
Computation
Machine Learning
IMPACT AREAS
Big Data
Finance
Healthcare / Medicine
Infrastructure
Manufacturing
Social Networks
Visit the Camera Culture Group site to learn more.